

How To Add To A Dataframe Pandas

In this article, I will use examples to bear witness you how to add columns to a dataframe in Pandas. There is more than one way of calculation columns to a Pandas dataframe, allow'due south review the main approaches.
Create a Dataframe
As usual allow's starting time past creating a dataframe.
Create a simple dataframe with a dictionary of lists, and column names: name, historic period, city, land.
# Creating simple dataframe # List of Tuples students = [ ('Jack', 34, 'Sydeny' , 'Commonwealth of australia') , ('Riti', 30, 'Delhi' , 'India' ) , ('Tom', 31, 'Mumbai' , 'India' ) , ('Neelu', 32, 'Bangalore' , 'India' ) , ('John', 16, 'New York' , 'The states') , ('Mike', 17, 'las vegas' , 'US') ] #Create a DataFrame object df = pd.DataFrame(students, columns = ['Name' , 'Age', 'City' , 'Land'], index=['a', 'b', 'c' , 'd' , 'e' , 'f']) 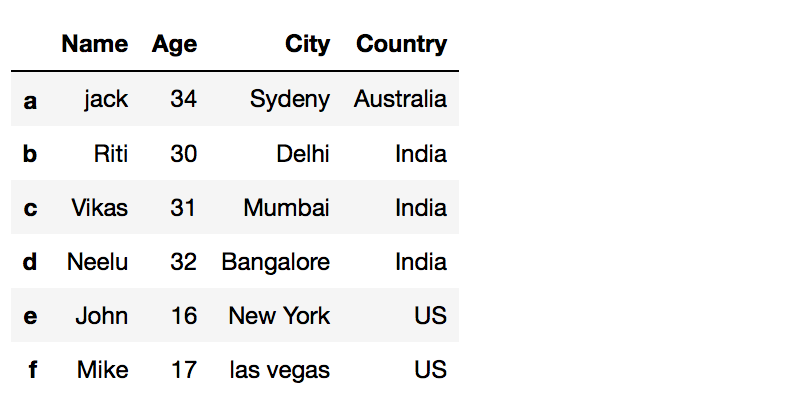
I. Add a column to Pandas Dataframe with a default value
When trying to gear up the entire column of a dataframe to a specific value, use 1 of the four methods shown below.
- By declaring a new
listingequally a column -
loc -
.assign() -
.insert()
Method I.1: By declaring a new list as a cavalcade
df['New_Column']='value' volition add the new column and set all rows to that value.
In this example, we will create a dataframe df and add a new column with the name Grade to it.
Your Dataframe before we add a new column:
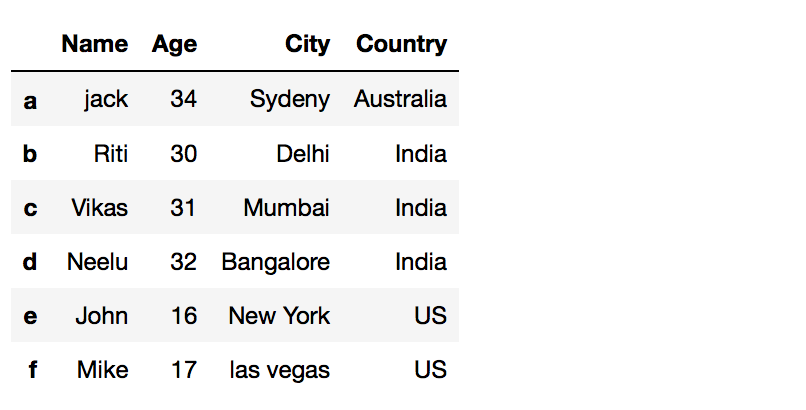
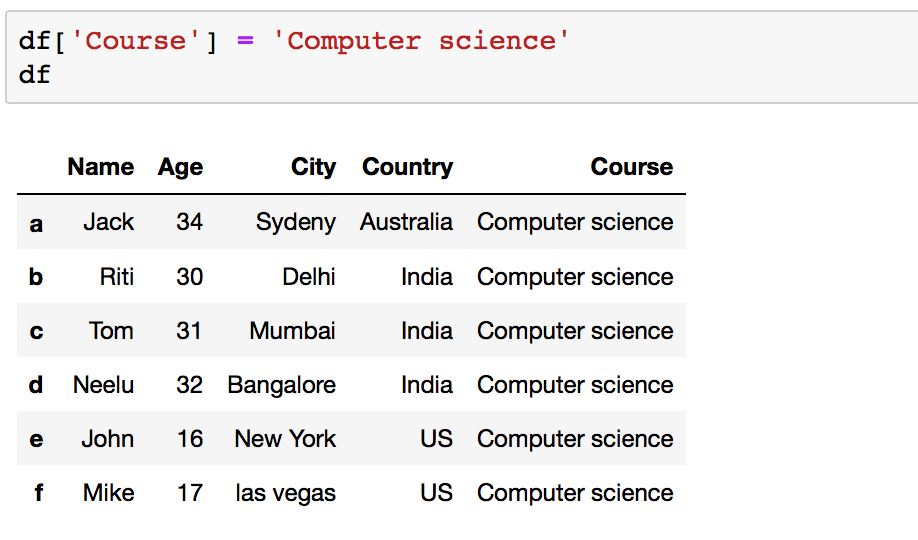
# Method 1: By declaring a new list as a cavalcade df['Course'] = 'Computer science' df Your Dataframe later adding a new cavalcade:
Some of you may go the following warning -
"A value is trying to be assail a re-create of a slice from a DataFrame".
This error is usually a result of creating a piece of the original dataframe before declaring your new column. To avoid the mistake add your new column to the original dataframe and then create the slice:
.loc[row_indexer,col_indexer] = value instead.
Python can do unexpected things when new objects are defined from existing ones. A slice of dataframe is but a stand-in for the rows stored in the original dataframe object: a new object is not created in retention.
To avoid these issues altogether use the copyor deepcopy module, which explicitly forces objects to be copied in retentivity then that methods chosen on the new objects are not applied to the source object.
Or you can use the .loc[] method as suggested by Pandas error bulletin.
For more information, come across the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html.
Method I.ii: Using .loc[]
The pandas.DataFrame.loc allows to access a grouping of rows and columns by characterization(s) or a boolean array.
.loc[] is primarily label based, but may also be used with a boolean array.
Allowed inputs are:
- A single label, e.g.
5or'a', (note that5is interpreted equally a characterization of the alphabetize, and never as an integer position along the index). - A listing or an array of labels, due east.1000.
['a', 'b', 'c']. - A slice object with labels, e.k.
'a':'f'.
df.loc[:,' - You can utilize '.loc' with ':' to add a specified value for all rows. New_Column'] = 'value'
Your Dataframe earlier we add a new column:
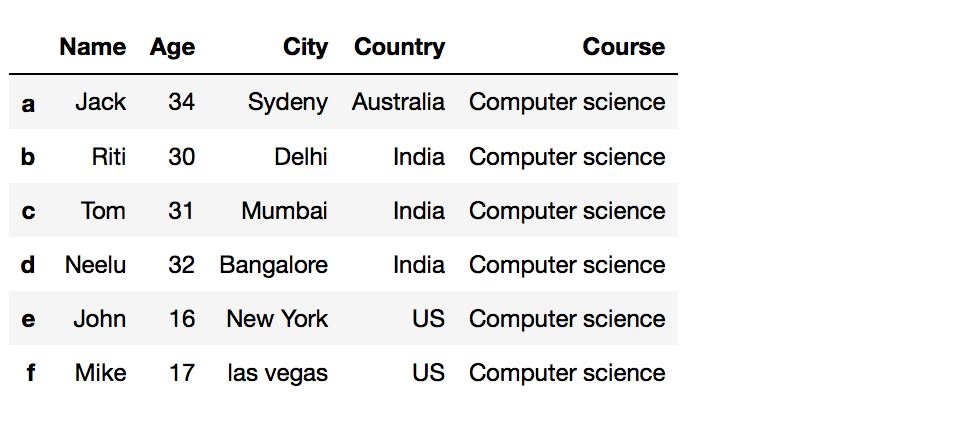
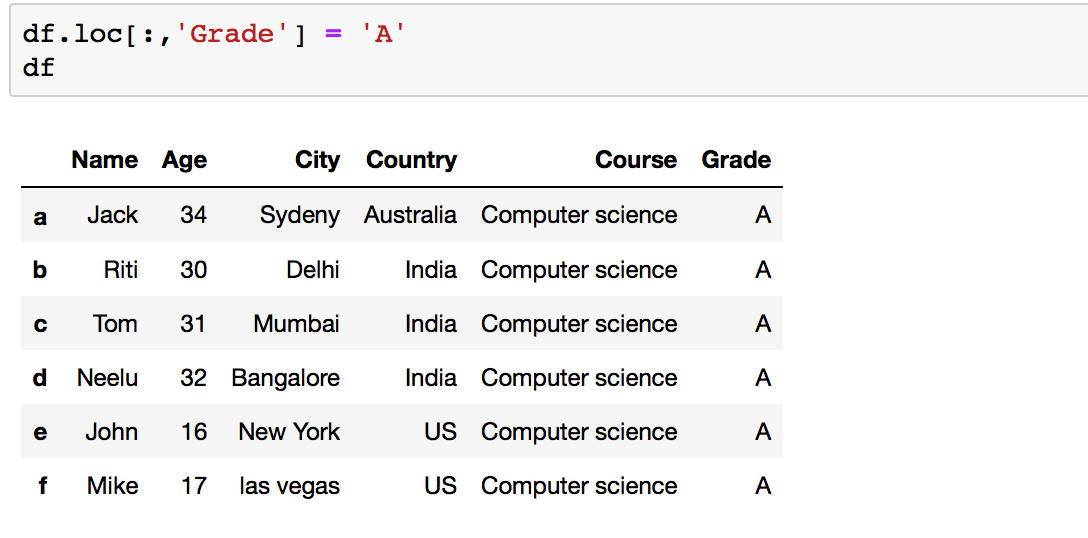
# Method two: Using .loc[] df.loc[:,'Grade'] = 'A' df Your Dataframe after adding a new column:
The .loc[] has two limitations: information technology mutates the dataframe in-place, and information technology can't be used with method chaining. If you are experiencing this problem, use the .assign() method.
Method I.3: Using the .assign() role
The .assign() function returns a new object with all original columns as well equally the new ones. Existing columns that are re-assigned will be overwritten. The cavalcade names are keywords. If the values are callable, they are computed on the dataframe and assigned to the new columns.
df = df.assign( ='value')New_Column
Your Dataframe before we add a new column:
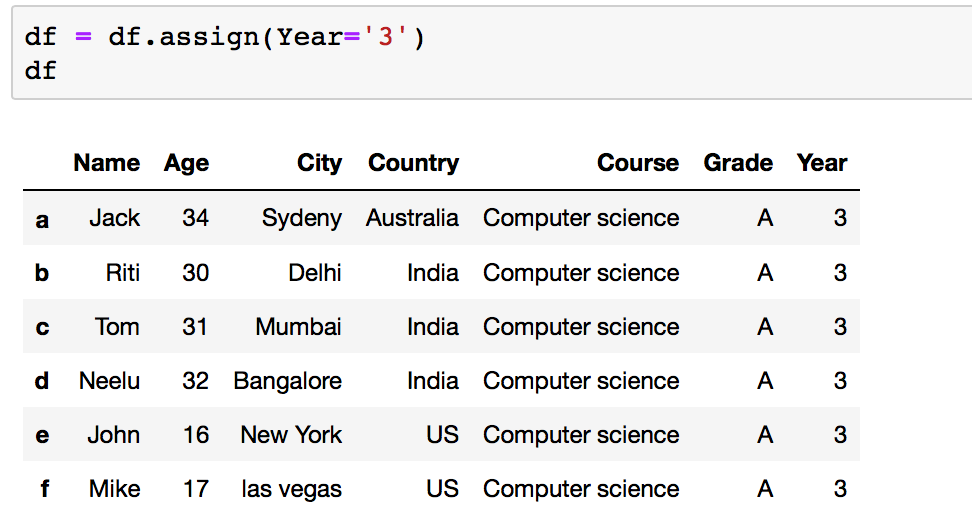
# Method iii: Using .assign() function df = df.assign(Year='3') df Your Dataframe after adding a new cavalcade:
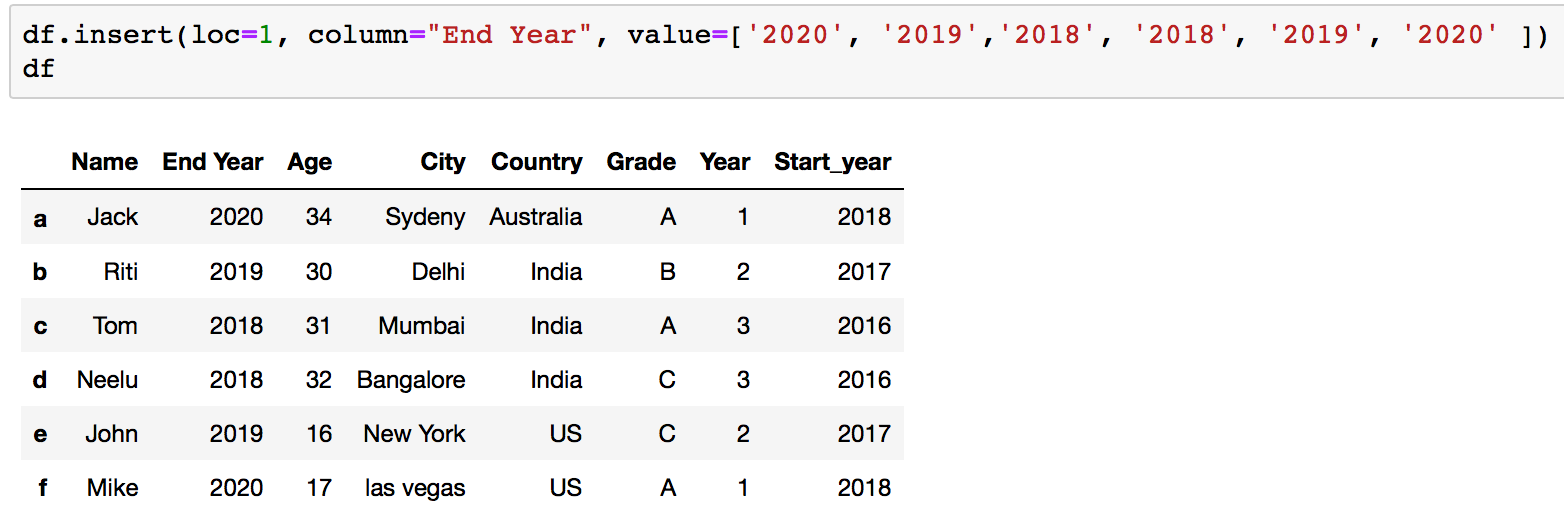
Method I.4: Using the .insert() function
An advantage of the .insert() method is that it gives the freedom to add a column at any position we similar and not just at the cease of the Dataframe. It also provides different options for inserting column values.
Parameters for .insert() :
- loc: loc is an integer which is the location of a column where we desire to insert a new column. This volition shift the existing column at that position to the correct.
- column: column is a string which is the name of a column to exist inserted.
- value: value is simply the value to be inserted. It can be an integer, a string, a float or even a serial / list of values. Providing only one value will fix the same value for all rows.
- allow_duplicates : allow_duplicates is a boolean value which checks wheather or not a column with the same name already exists.
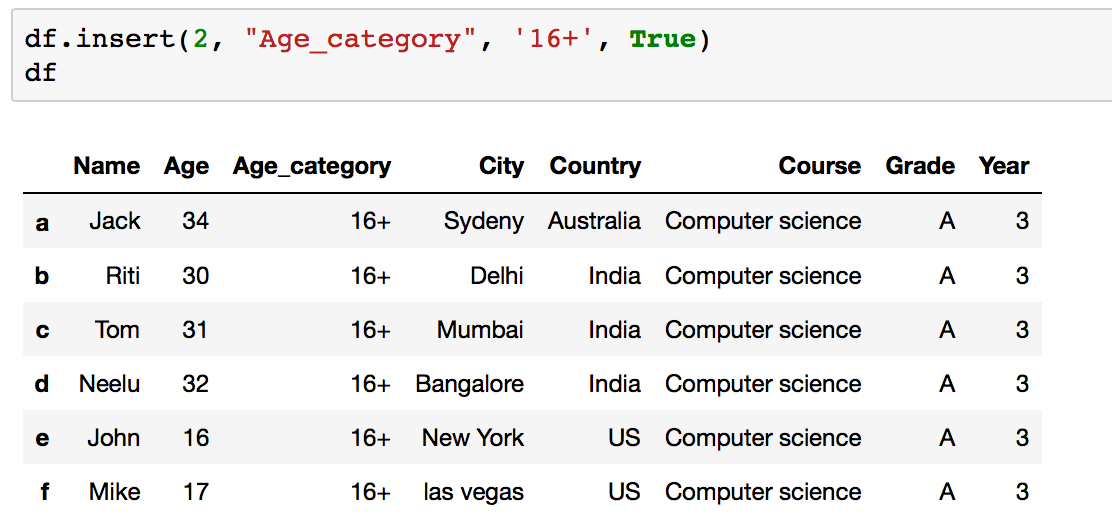
With the .insert() function you can set an entire column of a Dataframe to a specific value past - df.insert(2, 'New_Column', 'value', True)
Your Dataframe earlier we add a new column:
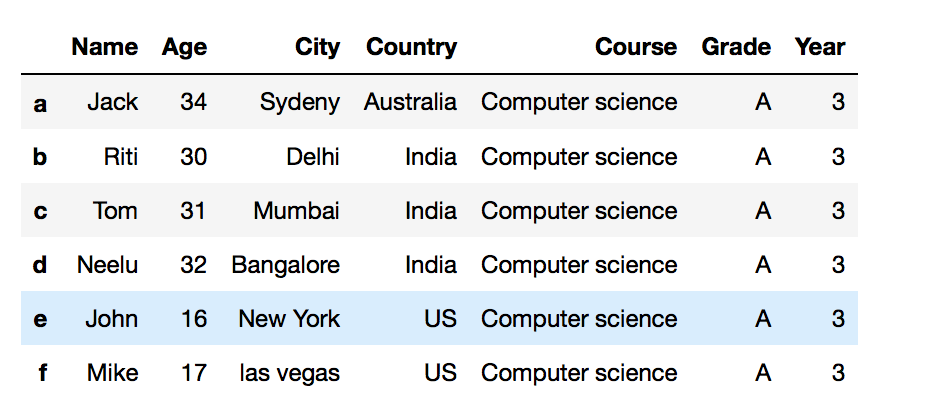
Your Dataframe after adding a new column:
II. Add a new column with dissimilar values
All the methods that are cowered above can also be used to assign a new column with dissimilar values to a dataframe.
Method II.one: By declaring a new list as a column
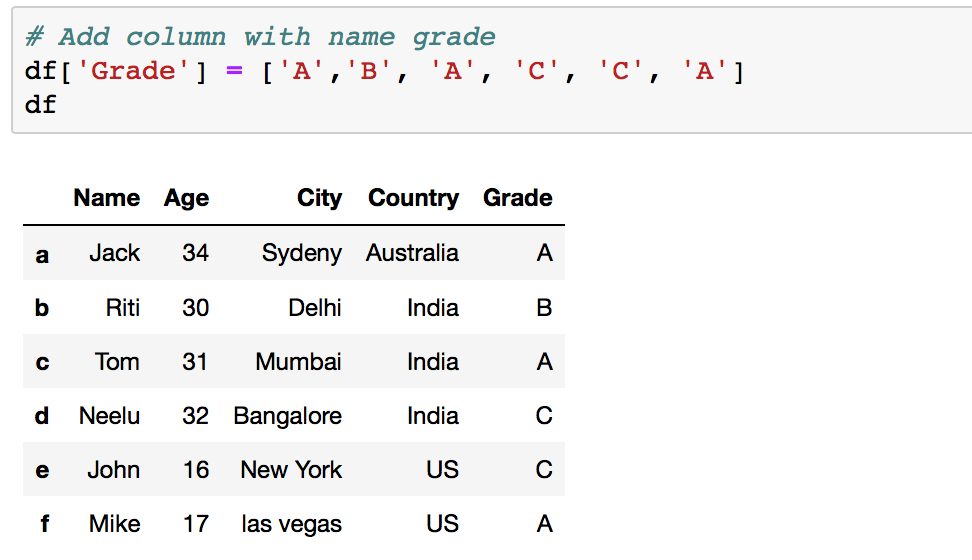
Y'all can append a new column with dissimilar values to a dataframe using method I.1 but with a list that contains multiple values. So instead of df['New_Column']='value' employ
df['New_Column']=['value1','value2','value iii']
When using this method you will need to keep the post-obit in listen:
- If values provided in the list are less than a number of indexes, then information technology will give a Value Error.
- If a column already exists, then all of its values volition exist replaced.
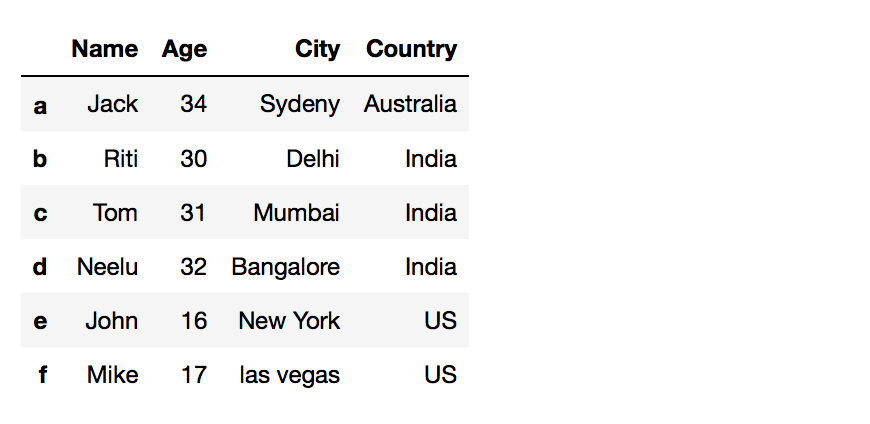
Your Dataframe before we add a new cavalcade:
Your Dataframe after calculation a new column:
Method 2.two: Using .loc[]
In this case you lot will need to change method I.ii
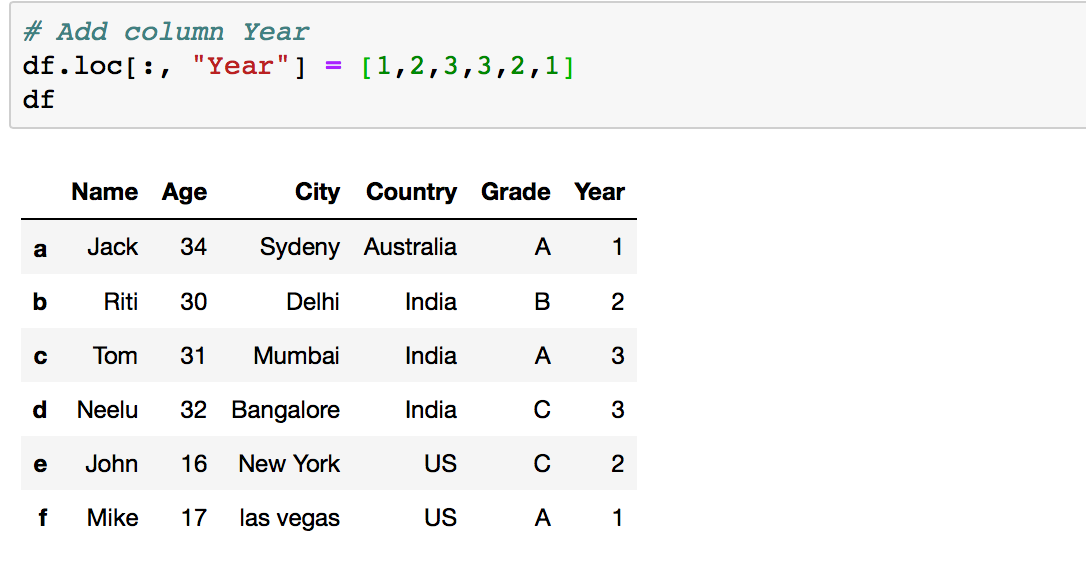
df.loc[:,' New_Column'] = 'value'
to
df.loc[:, ' '] = ['value1','value2','value3']New_Column
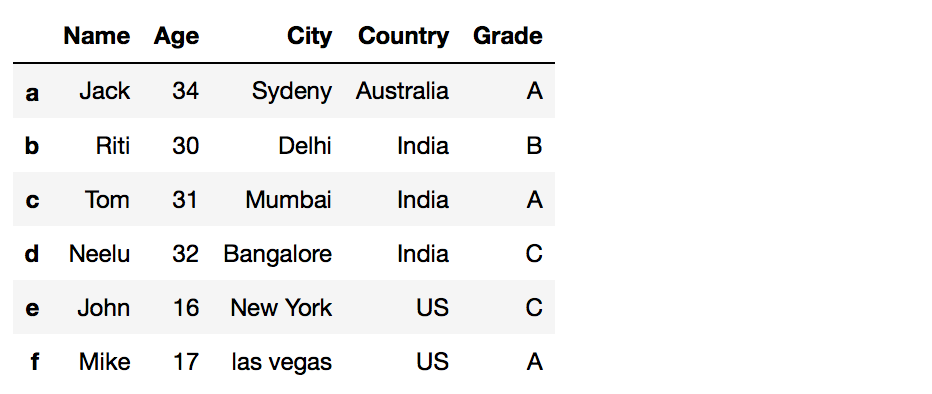
Your Dataframe before we add together a new column:
Your Dataframe after adding a new cavalcade:
Method 2.3 Using the .assign() function
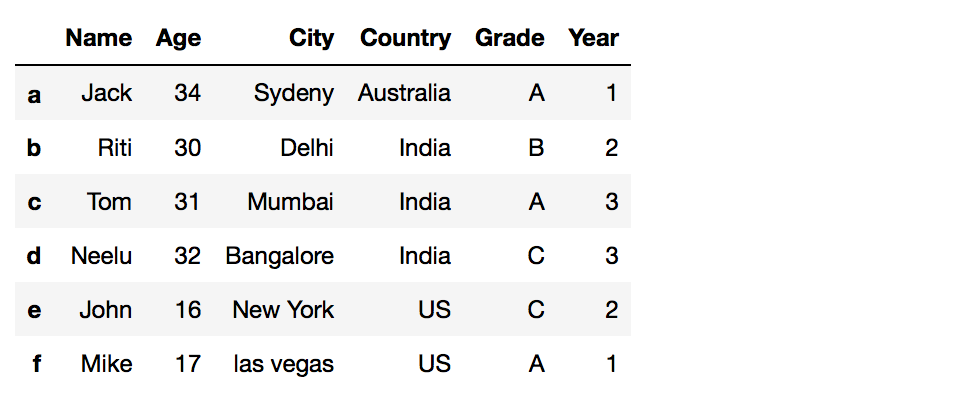
When you desire to add a new column with unlike values to a dataframe using the .assign() role you will need to alter
df = df.assign( ='value')New_Column
to
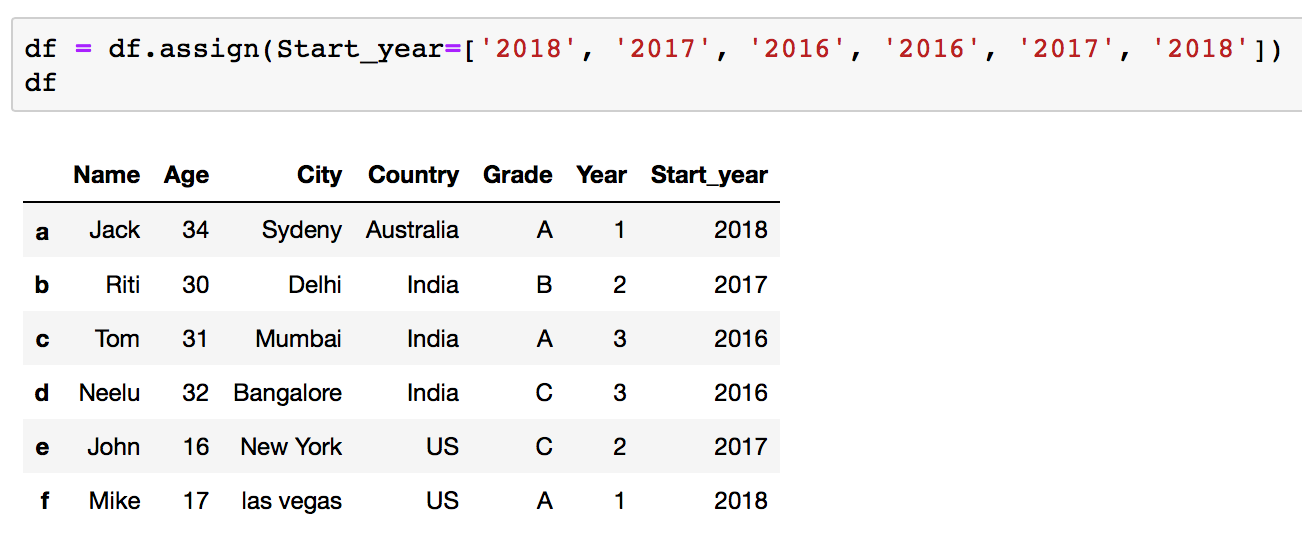
df = df.assign(New_column=['value1', 'value2', 'value3'])
Your Dataframe before we add a new column:
Your Dataframe later adding a new column:
Method 2.4 Using the .insert() function
You can use the.insert()role to inserting a column in a specific location. To add a new cavalcade with dissimilar values to a dataframe use:
df.insert(loc=i, column="New Column", value=['value1', 'value2','value3'])
Your Dataframe before we add a new cavalcade:
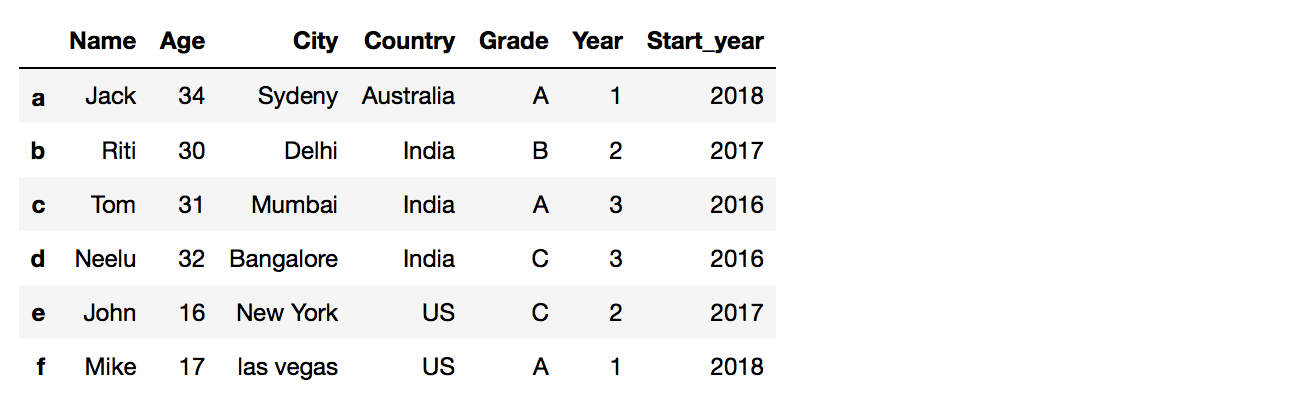
Your Dataframe after adding a new column:
Please note that in that location are many more means of adding a cavalcade to a Pandas dataframe. However, knowing these four should be more than sufficient.
Conclusion:
At present yous should sympathize the nuts of adding columns to a dataset in Pandas. I hope you've institute this post helpful. If you want to go deeper into the subject, there are some slap-up answers on StackOverflow.

How To Add To A Dataframe Pandas,
Source: https://re-thought.com/how-to-add-new-columns-in-a-dataframe-in-pandas/
Posted by: cooperallontention63.blogspot.com
0 Response to "How To Add To A Dataframe Pandas"
Post a Comment